Story Detection and Story Graph Visualization
Story Detection identifies and describes groups of related documents (= stories) from digital content streams. For each story, we extract a rich set of metadata. This includes the origin of the story in terms of publication time and author. We then evaluate the impact of the story by analyzing the temporal distribution of related publications. This analysis also helps to identify the best keywords to summarize the content of a story. As a final step, we visualize the results by creating an interactive Story Graph.
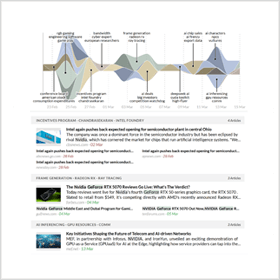
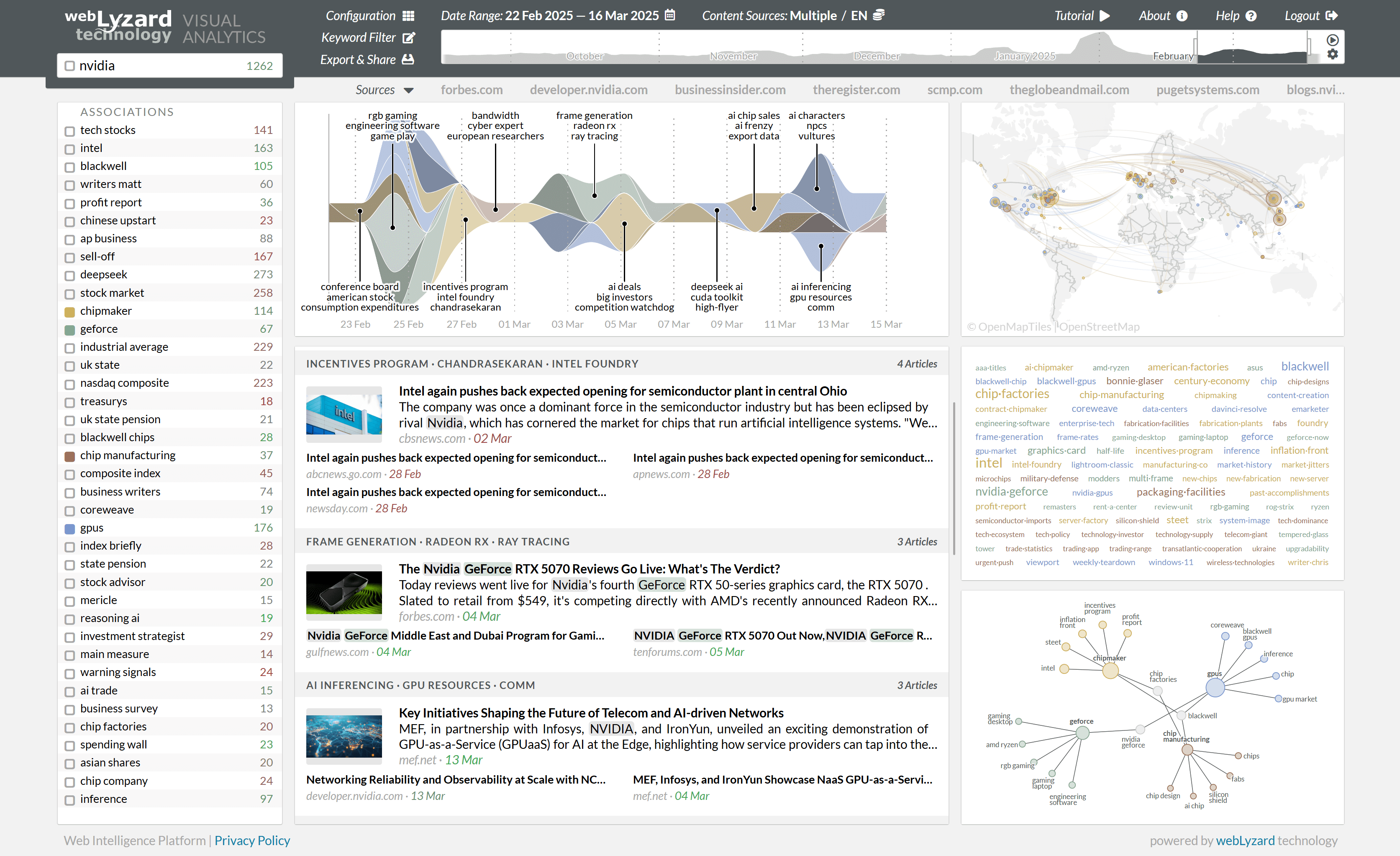
The following Story Graph illustrates this process using a query on “Nvidia”. The screenshot at the end of this article shows the Story Graph together with a list of top stories. For each story, this list includes a headline with the keywords and size of the cluster. Below the headline, a lead article and a list of related documents allow you to quickly understand the main aspects of the story.
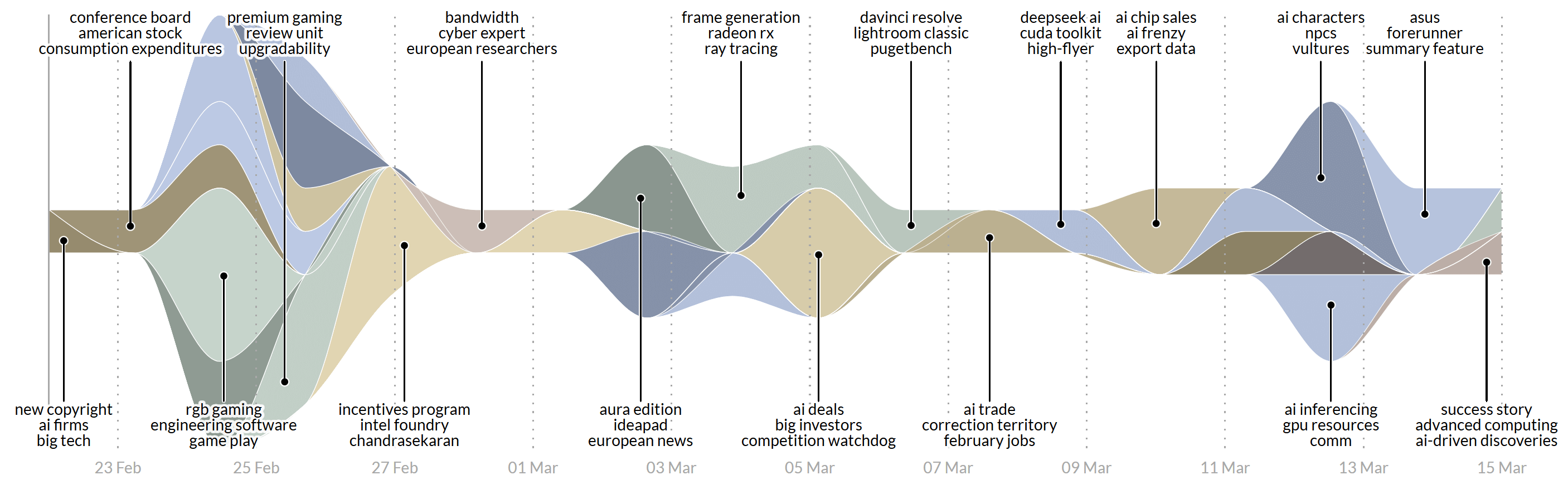
Clustering Digital Content Streams
The story detection component uses scalable methods to cluster documents in real time. These methods work with multiple content sources and languages. At the moment, the system supports English, Spanish, French, German, Dutch, Czech, Italian and Portuguese documents. Three keywords per cluster serve as a label to describe its contents. The methods to create these labels are not only multilingual, they are also effective dealing with noisy data. Examples for such noisy data include social media postings or results from speech-to-text conversion. Moreover, the clustering produces high-quality results even when applied to documents of very different structure and length.
Interactive Controls of the Story Graph
Story Graph Representation
- Tooltips. Hovering a story indicates its duration and the number of documents that belong to this story. Users can use the tooltip to either focus on this story, or exclude it from the query. Below, the tooltip shows the associated keywords. A synchronization mechanism automatically highlights the corresponding story in the Story View.
- Settings. The settings icon in the upper right corner provides various options to finetune the display of the graph. You can turn on and off the labels, for example, or select the metric to be used (document count or weight). Additional, it is possible to determine how the system should stack (silhouette, expand, zero, wiggle) and sort (default, inside-out, reverse) the stories.
Story Detection Result List
- Clicking on the title or snippet of an article activates its full-text view.
- Clicking on the name of the source opens a separate window with the original article or posting.
- The number of articles in the grey headline triggers a search for those articles. The arrow down expands the list of shown articles.
Last major update with release 2024-12 (Veiled Chameleon).