Research Projects and Funding Overview
The webLyzard platform has attracted research funding of more than EUR 18 million via competitive calls for advanced knowledge extraction and Web intelligence technologies from international (EU Horizon Europe, Horizon 2020 and 7th Framework Programme, Google DNI, CHIST-ERA) and national funding programs (Austrian Research Promotion Agency, BMK, Austrian Science Fund, Austrian Climate & Energy Fund, aws, Swiss Commission for Technology and Innovation, Swiss National Science Foundation).
Current Research Projects
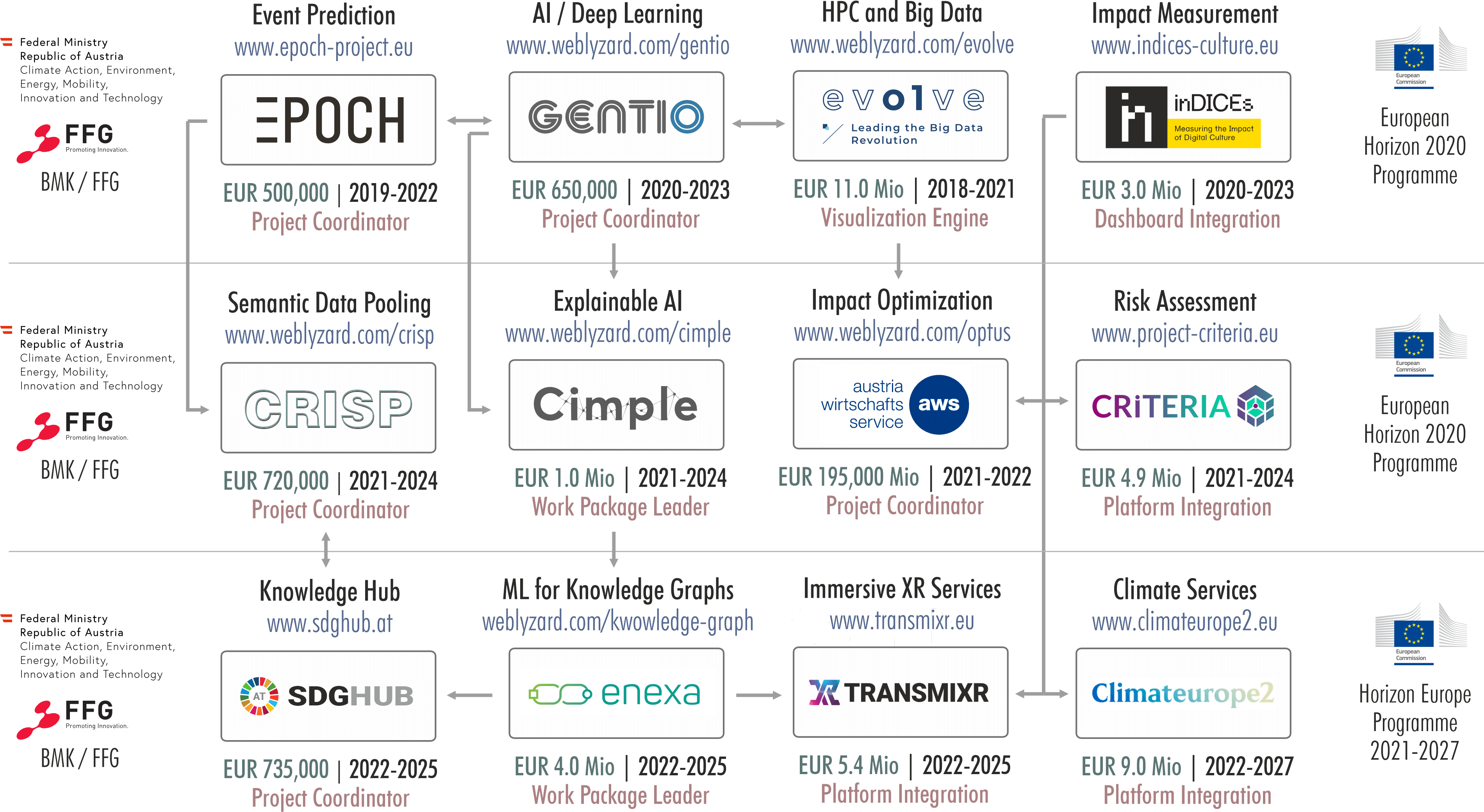
The following figure summarizes the ongoing R&D initiatives in European and national flagship programs, which provide an important resource base for webLyzard and ensure a consistently high rate of innovation.
Horizon Europe Projects
MultiPoD – Public Spaces for Citizen Deliberation. MultiPod develops methods to interconnect communities and increase the transparency of political deliberation. Leveraging core components of its architecture, including a Culture-Specific Language Model and a Culture-Specific Knowledge Graph, the project aims to bridge existing communication barriers, provide new tools for content co-creation, extract insights from collective intelligence and yield a better understanding of the interdependencies between policy decisions and participatory processes.
TransMIXR – Ignite the Immersive Media Sector by Enabling New Narrative Visions. TransMIXR creates human-centric tools for remote content production and consumption. The project’s TransMIXR platform will provide (i) a distributed XR Creation Environment that supports remote collaboration practices, and (ii) XR Media Experience Environment for the delivery and consumption of evocative and immersive media experiences. Ground-breaking AI techniques for understanding complex media content will enable the reuse of heterogeneous assets across immersive content delivery platforms. TransMIXR will develop and evaluate pilots that bring the vision of future media experiences to life in multiple domains: news media & broadcasting, performing arts and cultural heritage.
ENEXA – Efficient Explainable Learning on Knowledge Graphs. ENEXA builds upon novel and promising results in knowledge representation and machine learning to develop scalable, transparent and explainable machine learning algorithms for knowledge graphs. With new methods, ENEXA will advance in the efficiency and scalability of machine learning, especially on knowledge graphs and will focus on devising human-centered explainability techniques based on the concept of co-construction, where human and machine enter a conversation to jointly produce human-understandable explanations.
Climateurope2 – Supporting and Standardizing Climate services in Europe and Beyond. Climateurope2 will develop new approaches to classification and standardization to enhance the uptake of quality-assured climate services by all sectors of society. The increased adoption of these services will in turn support adaptation and mitigation efforts across Europe. The project will use webLyzard’s knowledge extraction capabilities to identify key actors and their services, elicit support and standardization needs, and classify strategies to trigger and support climate action. The resulting taxonomy of climate services will help promote community-focused best practices and guidelines.
Austrian Projects
TOPOKAT – Mapping the Austrian Crisis and Disaster Research Topology. The project will compile a data-driven overview of crisis and disaster research in Austria and reveal what the education landscape looks like. TOPOKAT combines webLyzard’s AI-powered media intelligence with social network analysis, a nationwide survey, and an interactive dashboard. Led by the Disaster Competence Network Austria (DCNA) with the Austrian Federal Ministries of Education and the Interior as stakeholders, the project aims to support the governance of research funding, education policy, and cross-sector knowledge transfer.
CLAIM – Hybrid AI Models for Claim Detection and Verification. The CLAIM project addresses growing concerns around false and misleading claims in global information networks. CLAIM is a human-centered effort to develop hybrid AI models to combat this problem, involving end-users in two use cases particularly affected by misinformation (false information spread inadvertently) and disinformation (spread with the intent to mislead): science journalism and stigma around mental health disorders. The project will streamline claim-checking workflows when reporting on complex and often contested issues and provide tools for journalists, mental health researchers, educators and other content creators to counter claims that lead to stigmatization and false beliefs.
GreenGLAM – Data Sculptures for Digital Heritage. The project develops AI-driven “Virtual Data Sculptures” to visualize the sustainability content of Galleries, Libraries, Archives, and Museums (GLAMs). These data sculptures aim to enhance visitors’ understanding of sustainability and promote the Sustainable Development Goals (SDGs). Additionally, GreenGLAM provides an analytics dashboard for cultural heritage professionals, integrating GLAM collection data with visitor interests to support effective management and engagement strategies.
SDG-HUB – AI-Driven Semantic Search and Visualization to Support the Sustainable Development Goals and Agenda 2030. SDG-HUB will build a knowledge hub to address the socio-ecological challenges to reaching the Sustainable Development Goals of the Agenda 2030 and the climate mitigation goals of the Paris Agreement. The project focuses on providing (i) concrete insights into problems and value systems that determine actions of social target groups as vital input for transdisciplinary dialogues with specific societal target groups, and (ii) input for monitoring and evaluation of Agenda 2030 & Paris Agreement progress.
AI-Centive – Incentivization for Sustainable Mobility. This “AI for Green” project builds a mobility data ecosystem to enable new incentivization approaches that promote sustainable mobility. The project’s core innovations help classify and customize incentives to reduce carbon emissions from fossil fuel-based means of transportation. AI models will help explain how and why citizens make certain mobility choices. Prediction methods will build on multidimensional context parameters such as weather, the location and duration of upcoming events, or the availability of environmentally friendly options.
KI.M – Climate-Neutral Urban Mobility builds a dynamic knowledge base that merges multimodal data using a domain-specific knowledge graph. The project integrates third-party data via an Eclipse Dataspace Connector (EDC) and webLyzard’s REST API. Enhanced by AI-driven knowledge extraction algorithms, the resulting repository increases the accuracy of mobility forecasting. A mobility dashboard enables policy makers (e.g., city officials) and corporate decision makers (e.g., moblity providers) to access this repository, promoting data reuse and encouraging collaboration across sectors.
Past Research Projects
A number of past research projects were funded by the EU Horizon 2020 and 7th Framework Programmes, the Swiss Commission for Technology and Innovation, as well as by the Austrian Research Promotion Agency. The projects aimed at radical innovations in the acquisition and management of unstructured data, the automation of information processes, human-computer interaction, and the integration of distributed information resources.

CRISP – Crisis Response and Intervention Supported by Semantic Data Pooling addresses the challenges of natural disasters in a data-driven manner, enabling more effective crisis response and intervention. CRISP considers both the short-term management of disasters as well as long-term economic impact assessments, at fine-grained regional and temporal granularity. CRISP will extract and classify disaster signals and perceptions from news and user-generated social media content, combine this data with weather and climate observations, and provide warnings and forecasts for disaster control authorities, and rescue organizations.
DWBI – A Digital Well-Being Index for Vienna. Funded by the Digital Humanism Program of the Vienna Science and Technology Fund (WWTF), this was a joint research undertaking of the Research Center for New Media Technology and the Department of Sustainability, Governance and Methods of Modul University Vienna. The three-year project used the semantic technology stack of webLyzard to develop new knowledge extraction algorithms. The goal was to accurately measure well-being in the Vienna region, and to compare the obtained results with those of other selected cities. A visual analytics dashboard will help to better understand patterns and changes in subjective well-being by region and over time.
EPOCH – Event Prediction from Hybrid Datasets. The EPOCH project measured the effects on statistical indicators of events being reported in the news and social media. Innovatively, it used the measured effects of now past events to predict the future changes expected due to future events detected in the public dialogue. Through the EPOCH dashboard, organizations can identify and thus better prepare for these changes, adapting their communications, marketing and resources accordingly.
CommuniData – Open Data for Local Communities. This project addressed the problem that only a minority of citizens regularly participate in collective decisions. Its goal was to enable a data-driven approach to collective decision-making that translates Open Data into actionable knowledge for physical, local communities and connects administrations and citizens through an integrated Urban Participation Platform. It also provided novel visualization tools to navigate and better understand patterns in this knowledge repository, and enabled communities to find, co-create and discuss Open Data to solve, e.g. urban sustainability challenges in a collaborative fashion.
EcoMove – Mobility Project. To address urban mobility challenges, EcoMove developed knowledge-based solutions for efficient and environmentally sustainable movement in cities, providing customized information about available mobility options. Real-time recommendations for delaying, avoiding or taking alternative options were presented visually to the users – city residents, visitors, and professional stakeholders – in order to prioritize “necessary” mobility.
inDICEs – Measuring the Impact of Digital Culture aims to empower policy makers and professional stakeholders in the cultural and creative industries, helping them to fully understand the social and economic impact of digitization on their sector. The project addresses the need for innovative (re)use of cultural assets, and for new tools to monitor engagement and public perception of these assets.
GENTIO – Generative Learning Networks for Text & Impact Optimization aims to change the way we produce, enrich and analyze digital content. The project will develop a deep learning architecture to unify the understanding of text at three fundamental levels: structure, content and context. This will yield quantitative methods to maximize the impact of data-driven publishing.
CRiTERIA – Comprehensive Data-Driven Risk and Threat Assessment Methods (EU H2020) seeks to strengthen and expand existing risk analysis methods by introducing new computational approaches based on qualitative evidence (e.g., narrative analysis) in conjunction with composite indicators such as sentiment analysis and prediction, taking into account risk interaction and risk cascading assessments.
CIMPLE – Countering Creative Information Manipulation with Explainable AI draws on models of human creativity, both in manipulating and understanding information, to design understandable and personalizable explanations. CIMPLE will use computational creativity techniques to generate powerful, engaging, and easily and quickly understandable explanations of complex AI decisions and behavior. These explanations will be tested in the domain of detection and tracking of manipulated information, taking into account social, psychological and technical explainability needs and requirements.
ReTV – Enhancing and Re-Purposing TV Content for Trans-Vector Engagement. The project developed new methods for media organizations to dynamically re-purpose content for a wide range of digital channels. The aim is to “publish to all media vectors with the effort of one”. ReTV empowers broadcasters and brands to continuously measure and predict their success in terms of reach and audience engagement. webLyzard leads the ReTV system integration, leveraging its existing portfolio of visual analytics components. As part of the project, we also developed the Storypact Editor to expand the predictive capabilities of our platform.
![]() SONAR – Semantic Observatory for News Analytics and Repurposing. The project is a joint initiative of ProSiebenSat.1 PULS 4 and webLyzard to support balanced news reporting and increase the impact of digital content assets. It will provide real-time visualization services for journalists, including specific recommendations on where and how to publish digital assets containing these visualizations. This will not only guide the production of new content, but also the repurposing of existing digital assets.
SONAR – Semantic Observatory for News Analytics and Repurposing. The project is a joint initiative of ProSiebenSat.1 PULS 4 and webLyzard to support balanced news reporting and increase the impact of digital content assets. It will provide real-time visualization services for journalists, including specific recommendations on where and how to publish digital assets containing these visualizations. This will not only guide the production of new content, but also the repurposing of existing digital assets.
![]() InVID (In Video Veritas) – Verification of Social Media Video Content for the News Industry. This Innovation Action started in January 2016 and builds a Web-based application to automatically identify newsworthy video content spread via social media, and confirm or reject its credibility using state-of-the-art analytical techniques. webLyzard leads the development of the application and the overall system integration, leveraging the existing video retrieval capabilities of its Web Intelligence platform.
InVID (In Video Veritas) – Verification of Social Media Video Content for the News Industry. This Innovation Action started in January 2016 and builds a Web-based application to automatically identify newsworthy video content spread via social media, and confirm or reject its credibility using state-of-the-art analytical techniques. webLyzard leads the development of the application and the overall system integration, leveraging the existing video retrieval capabilities of its Web Intelligence platform.
![]() Pheme – Computing Veracity across Media, Languages, and Social Networks. Analyzing big data repositories aggregated from context-dependent social media streams poses three major computational challenges: volume, velocity, and variety. This project focuses on a fourth, largely unstudied computational challenge: veracity. It will model and verify phemes (Internet memes with added information on truthfulness or deception) as they spread across media, languages, and social networks.
Pheme – Computing Veracity across Media, Languages, and Social Networks. Analyzing big data repositories aggregated from context-dependent social media streams poses three major computational challenges: volume, velocity, and variety. This project focuses on a fourth, largely unstudied computational challenge: veracity. It will model and verify phemes (Internet memes with added information on truthfulness or deception) as they spread across media, languages, and social networks.
![]() DISCOVER – Knowledge Discovery, Extraction and Fusion for Improved Decision Making. The research project develops methods for the automatic acquisition, extraction and integration of decision-relevant information from heterogeneous online sources. The system uses background knowledge from domain ontologies, databases, and an information value model to optimize knowledge acquisition processes from websites and deep web repositories. The extracted knowledge is then integrated with business information systems to optimize decision-making and business processes.
DISCOVER – Knowledge Discovery, Extraction and Fusion for Improved Decision Making. The research project develops methods for the automatic acquisition, extraction and integration of decision-relevant information from heterogeneous online sources. The system uses background knowledge from domain ontologies, databases, and an information value model to optimize knowledge acquisition processes from websites and deep web repositories. The extracted knowledge is then integrated with business information systems to optimize decision-making and business processes.
![]() ASAP – Adaptable Scalable Analytics Platform. The project develops an open-source execution framework for scalable data analytics. It assumes that no single execution model is suitable for all types of tasks, and that no single data model is suitable for all types of data. ASAP will provide resource elasticity, fault-tolerance and the ability to handle large sets of irregular distributed data. Within ASAP, webLyzard is responsible for the visualization engine and leads the dissemination and exploitation work package.
ASAP – Adaptable Scalable Analytics Platform. The project develops an open-source execution framework for scalable data analytics. It assumes that no single execution model is suitable for all types of tasks, and that no single data model is suitable for all types of data. ASAP will provide resource elasticity, fault-tolerance and the ability to handle large sets of irregular distributed data. Within ASAP, webLyzard is responsible for the visualization engine and leads the dissemination and exploitation work package.
![]() DecarboNet – A Decarbonisation Platform for Citizen Empowerment and Translating Collective Awareness into Behavioural Change. This project will identify determinants of collective awareness, trigger behavioral change, and provide novel methods to analyze the underlying processes. Innovations are built around a context-specific repository of carbon reduction strategies. To refine this repository, we will utilize citizen-generated content in a societal feedback loop to enable an adaptive process of social innovation.
DecarboNet – A Decarbonisation Platform for Citizen Empowerment and Translating Collective Awareness into Behavioural Change. This project will identify determinants of collective awareness, trigger behavioral change, and provide novel methods to analyze the underlying processes. Innovations are built around a context-specific repository of carbon reduction strategies. To refine this repository, we will utilize citizen-generated content in a societal feedback loop to enable an adaptive process of social innovation.
![]() IMAGINE – The retrieval and marketability of visual content highly depend on the availability of high-quality metadata, enabling customers to locate the most relevant content in large image collections. The project exploits the convergence of textual image descriptions, image content and linked open data to automatically obtain relevant metadata including keywords, named entities, and reference topics.
IMAGINE – The retrieval and marketability of visual content highly depend on the availability of high-quality metadata, enabling customers to locate the most relevant content in large image collections. The project exploits the convergence of textual image descriptions, image content and linked open data to automatically obtain relevant metadata including keywords, named entities, and reference topics.
![]() uComp – Embedded Human Computation for Knowledge Extraction and Evaluation. The project merges collective human intelligence and automated knowledge extraction methods in a symbiotic fashion, drawing upon both games with a purpose and crowdsourcing marketplaces. It develops a scalable human computation framework for knowledge extraction and evaluation, delegating the most challenging tasks to large user communities and learning from user feedback to optimize automated methods as part of an iterative process.
uComp – Embedded Human Computation for Knowledge Extraction and Evaluation. The project merges collective human intelligence and automated knowledge extraction methods in a symbiotic fashion, drawing upon both games with a purpose and crowdsourcing marketplaces. It develops a scalable human computation framework for knowledge extraction and evaluation, delegating the most challenging tasks to large user communities and learning from user feedback to optimize automated methods as part of an iterative process.
![]() RMCS – Radar Media Criticism Switzerland. The project develops a research infrastructure and establishes knowledge transfer mechanisms to conduct automated content analyses and assess the structure and content of media criticism in Switzerland. The radar will identify the most important institutional players, track influential media blogs and opinion leaders across social media platforms, and help to assess the diversity of topics, actors, and opinions from a communications and media science perspective.
RMCS – Radar Media Criticism Switzerland. The project develops a research infrastructure and establishes knowledge transfer mechanisms to conduct automated content analyses and assess the structure and content of media criticism in Switzerland. The radar will identify the most important institutional players, track influential media blogs and opinion leaders across social media platforms, and help to assess the diversity of topics, actors, and opinions from a communications and media science perspective.
![]() WISDOM – Web Intelligence for Improved Decision Making. Obtaining accurate business intelligence that supports data-driven decision making helps to optimize corporate strategies and gain a competitive advantage. WISDOM draws upon Web intelligence methods to integrate data from news media and social sources, develops context-aware information extraction techniques to identify stakeholders and their sentiment towards emerging trends, and provides novel performance and reliability metrics that enhance decision making processes.
WISDOM – Web Intelligence for Improved Decision Making. Obtaining accurate business intelligence that supports data-driven decision making helps to optimize corporate strategies and gain a competitive advantage. WISDOM draws upon Web intelligence methods to integrate data from news media and social sources, develops context-aware information extraction techniques to identify stakeholders and their sentiment towards emerging trends, and provides novel performance and reliability metrics that enhance decision making processes.
![]() COMET – Cross-Media Extraction of Unified High Quality Marketing Data. Knowledge resources with clear economic value are spread across multiple channels such as print media, Web documents, blogs, and social media. The COMET project develops key technologies for combining and analyzing such heterogeneous and multimodal channels. Automated consolidation, classification and sentiment analysis support the extraction of marketing information, and aid decision makers in optimizing their branding and marketing strategies.
COMET – Cross-Media Extraction of Unified High Quality Marketing Data. Knowledge resources with clear economic value are spread across multiple channels such as print media, Web documents, blogs, and social media. The COMET project develops key technologies for combining and analyzing such heterogeneous and multimodal channels. Automated consolidation, classification and sentiment analysis support the extraction of marketing information, and aid decision makers in optimizing their branding and marketing strategies.
![]() DIVINE – Dynamic Integration and Visualization of Information from Multiple Evidence Sources. DIVINE integrates data from structured, unstructured and social sources to build information spaces. Lightweight seed ontologies act as focal points for integrating new evidence from third-party sources. Since such evidence is inherently uncertain, source-specific transformation rules assign confidence values to newly acquired pieces of knowledge.
DIVINE – Dynamic Integration and Visualization of Information from Multiple Evidence Sources. DIVINE integrates data from structured, unstructured and social sources to build information spaces. Lightweight seed ontologies act as focal points for integrating new evidence from third-party sources. Since such evidence is inherently uncertain, source-specific transformation rules assign confidence values to newly acquired pieces of knowledge.
![]() RAVEN – Relation Analysis and Visualization for Evolving Networks. RAVEN keeps analysts and decision-makers up-to-date about the unfolding of events in endogenous and exogenous information spaces, which reflect interconnected events and processes of the real world. RAVEN aims to understand the evolution of such spaces by analyzing temporal-semantic relations between their elements.
RAVEN – Relation Analysis and Visualization for Evolving Networks. RAVEN keeps analysts and decision-makers up-to-date about the unfolding of events in endogenous and exogenous information spaces, which reflect interconnected events and processes of the real world. RAVEN aims to understand the evolution of such spaces by analyzing temporal-semantic relations between their elements.
![]() IDIOM – Information Diffusion across Interactive Online Media: Linguists define “idiom” as expression whose meaning is different from the literal meanings of its component words. Similarly, the study of information diffusion promises insights that cannot be inferred from individual network elements. Media monitoring projects often focus on a particular medium, or neglect important aspects of the human language. IDIOM addresses these gaps to reveal fundamental mechanisms of information diffusion across media with distinct interactive characteristics.
IDIOM – Information Diffusion across Interactive Online Media: Linguists define “idiom” as expression whose meaning is different from the literal meanings of its component words. Similarly, the study of information diffusion promises insights that cannot be inferred from individual network elements. Media monitoring projects often focus on a particular medium, or neglect important aspects of the human language. IDIOM addresses these gaps to reveal fundamental mechanisms of information diffusion across media with distinct interactive characteristics.
![]() AVALON – Acquisition and Validation of Ontologies: Valuable knowledge that surrounds the workflows of business entities can be extracted automatically and represented as ontological structure. AVALON services build upon a cybernetic control system to automatically align extracted knowledge with business processes, external indicators and individual expertise. Such services are particularly useful in volatile business environments, which require dynamic reconfiguration of business processes and a flexible allocation of resources.
AVALON – Acquisition and Validation of Ontologies: Valuable knowledge that surrounds the workflows of business entities can be extracted automatically and represented as ontological structure. AVALON services build upon a cybernetic control system to automatically align extracted knowledge with business processes, external indicators and individual expertise. Such services are particularly useful in volatile business environments, which require dynamic reconfiguration of business processes and a flexible allocation of resources.
![]() European eContent Tourism Survey. Longitudinal survey on behalf of the Austrian Federal Economic Chamber, which contrasted a sample of 500 Austrian tourism sites with the international competition. Selected results were presented at the European Forum Alpbach in August 2001.
European eContent Tourism Survey. Longitudinal survey on behalf of the Austrian Federal Economic Chamber, which contrasted a sample of 500 Austrian tourism sites with the international competition. Selected results were presented at the European Forum Alpbach in August 2001.