
PHEME – Lie Detector for Social Media
Barack Obama was not born in the USA! Or was he? Social networks are rife with lies and deception, half-truths and myths. But irrespective of whether a story turns out to be fact or fake, its rapid spread can have unexpected and far-reaching consequences. The PHEME project sheds light on the underlying information diffusion processes.
PHEME Project Overview
 The PHEME project assesses the truthfulness of stories that go viral on social media platforms. the project is a research initiative carried out within the European 7th Framework Programme (FP7). With a duration of three years and a budget of EUR 2.9 million, the project enables researchers from seven different countries to tackle the problem with a multi-disciplinary approach. PHEME combines big data analytics with advanced linguistic and text mining methods. The results are applicable across domains, but were first evaluated in three use cases: medicine, digital journalism, and climate science communication. In May 2015, leading international researchers met at the 24th International World Wide Web Conference, where the PHEME consortium organized the RDSM-2015 Workshop on Rumour Detection in Social Media.
The PHEME project assesses the truthfulness of stories that go viral on social media platforms. the project is a research initiative carried out within the European 7th Framework Programme (FP7). With a duration of three years and a budget of EUR 2.9 million, the project enables researchers from seven different countries to tackle the problem with a multi-disciplinary approach. PHEME combines big data analytics with advanced linguistic and text mining methods. The results are applicable across domains, but were first evaluated in three use cases: medicine, digital journalism, and climate science communication. In May 2015, leading international researchers met at the 24th International World Wide Web Conference, where the PHEME consortium organized the RDSM-2015 Workshop on Rumour Detection in Social Media.
Rumour Mill 2.0
Traditional media channels do no longer act as the sole gatekeepers who select newsworthy events and developments. Social media have an increasing influence on information diffusion processes. An ant quickly becomes an elephant, or a sneeze inflates into the threat of a global pandemic.
Coined by the evolutionary biologist Richard Dawkins in 1976 [1], the term “meme” stands for an idea or behavior that spreads among members of a community. Viral effects can amplify the spread of memes in virtual communities. This poses new challenges for policymakers and corporate decision makers. These stakeholders will be the main beneficiaries of the new technologies to be developed within the PHEME project (in Greek mythology, PHEME referred to the goddess of fame who made people she favored notable and renowned, but those who defied here the target of rumours).
Four ‘Vs’ of Big Data Analysis
 Volume, variety and velocity – the three ‘Vs’ of big data analysis – represent obstacles for the automated analysis of digital content from social media. Obstacles that the webLyzard Web intelligence platform has successfully addressed. The PHEME project focuses on the fourth ‘V’: the veracity of the acquired knowledge.
Volume, variety and velocity – the three ‘Vs’ of big data analysis – represent obstacles for the automated analysis of digital content from social media. Obstacles that the webLyzard Web intelligence platform has successfully addressed. The PHEME project focuses on the fourth ‘V’: the veracity of the acquired knowledge.
Novel visualization techniques embedded in the PHEME dashboard help to identify and track four types of dubious truth or rumour: speculation, controversy, misinformation and disinformation.
Building upon previous research [2] into the diffusion of information across online media, a combination of text mining and social network analysis reveals veracity in three consecutive steps: (i) analyze the information contained in the document, (ii) cross-reference extracted facts with trustworthy data sources, and (iii) trace the propagation of information among network nodes.
PHEME Use Cases
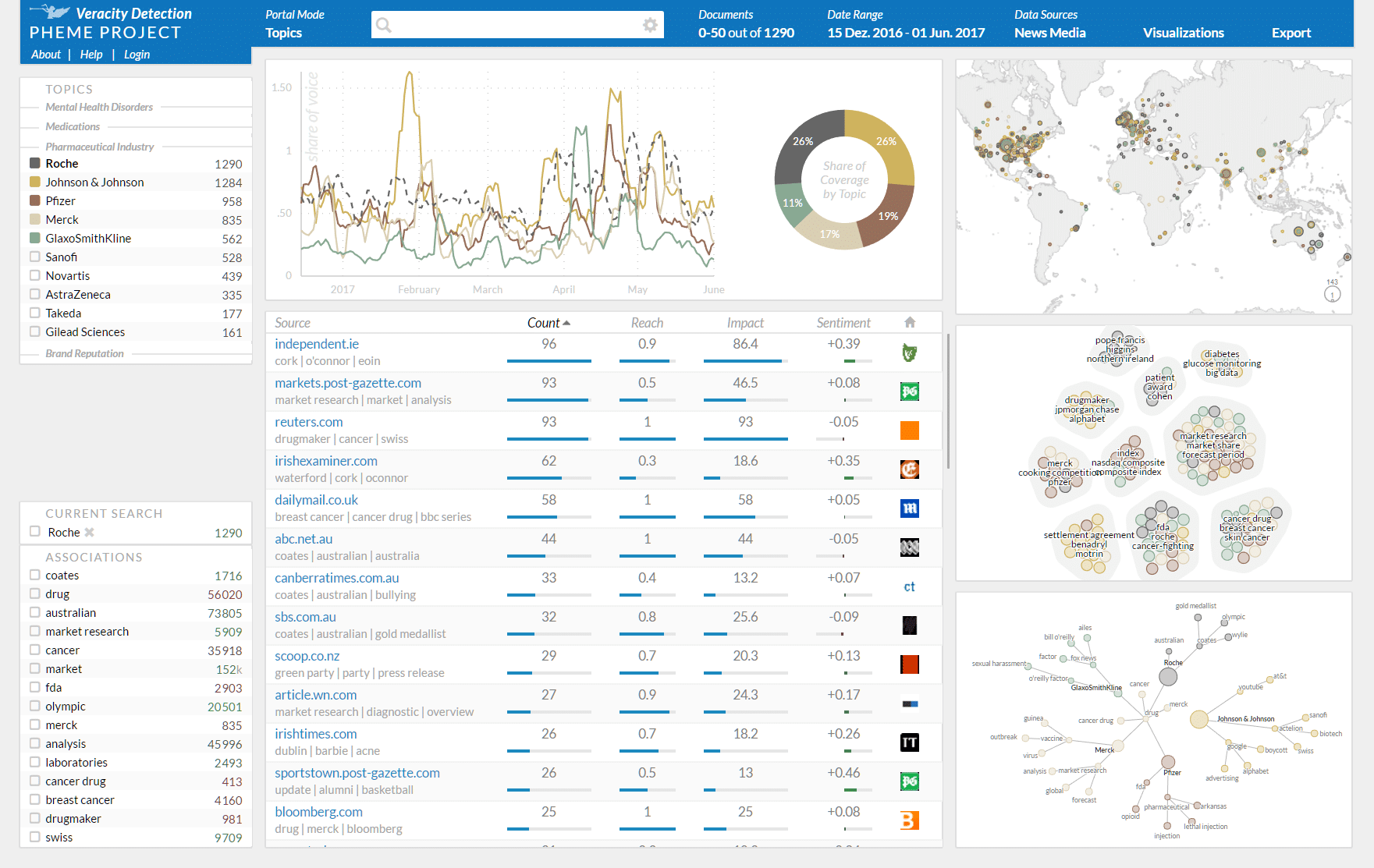
The social context of storytelling has a significant impact on the diffusion of memes. We have tested the described set of “rumour intelligence” methods in three specific domains (the figure below shows a screenshot of the current webLyzard dashboard that has been adopted for visualizing PHEME results):
- Medicine – outbreak and spread of a contagious disease, e.g. swine flu;
- Digital Journalism – workflow improvements e.g. for breaking stories;
- Climate Science – e.g., filter for the veracity of statements about the causes and impacts of climate change (extending the advanced search capabilities of the Media Watch on Climate Change).
Project Consortium
 The PHEME research project was funded by the European Commission (EC) within the 7th Framework Programme (FP7) under Project No. 611233. It started on 01 Jan 2014 with a duration of 36 months. The consortium includes the following organizations: University of Sheffield (UK), MODUL University Vienna (AT), Saarland University (DE), King’s College (UK), University of Warwick (UK), Ontotext (BG), ATOS (ES), iHub (KE), and Swissinfo (CH).
The PHEME research project was funded by the European Commission (EC) within the 7th Framework Programme (FP7) under Project No. 611233. It started on 01 Jan 2014 with a duration of 36 months. The consortium includes the following organizations: University of Sheffield (UK), MODUL University Vienna (AT), Saarland University (DE), King’s College (UK), University of Warwick (UK), Ontotext (BG), ATOS (ES), iHub (KE), and Swissinfo (CH).

")

")
")
References
- Dawkins, R. (1976). The Selfish Gene. Oxford: Oxford University Press.
- Scharl, A., Weichselbraun, A. and Liu, W. (2007). “Tracking and Modelling Information Diffusion across Interactive Online Media“, International Journal of Metadata, Semantics and Ontologies, 2(2): 136-145.
- Scharl, A., Hubmann-Haidvogel, A., Jones, A., Fischl, D., Kamolov, R., Weichselbraun, A. and Rafelsberger, W. (2016). “Analyzing the Public Discourse on Works of Fiction – Automatic Emotion Detection in Online Media Coverage about HBO’s Game of Thrones“, Information Processing & Management, 52(1): 129-138 [Best Paper Award – Honorable Mention].
- Scharl, A., Weichselbraun, A., Göbel, M., Rafelsberger, W. and Kamolov, R. (2016). “Scalable Knowledge Extraction and Visualization for Web Intelligence“, 49th Hawaii International Conference on System Sciences (HICSS-2016). Kauai, USA: IEEE Press. 3749-3757 [Best Paper Award].
- Hager, L. (2017). “Algorithmen gegen Fake News“, Statement, May/June 2017. 14-15.
