Big Data and Scalable Analytics
The webLyzard Web intelligence platform is built on highly scalable knowledge extraction and content recommendation services. In conjunction with the rapid response times of the visual dashboard and its award-winning synchronization mechanisms, these scalable analytics services enable analysts to conduct market research and explore large knowledge repositories at the touch of a button.
At webLyzard, ensuring scalability for high-throughput Web applications has been a fundamental design principle from day one. This acknowledges that scalability cannot be addressed at the system level alone, but needs to guide the development of algorithms and interface components as well. The optimized knowledge processing workflow includes a number of core components including:
- Data Acquisition and Integration. A dynamic crawling and pre-processing architecture offers superior metadata handling (e.g., when gathering social media content) and caching control, and is perfectly suited for deployment in distributed environments.
- Information Retrieval. The webLyzard search and indexing engine provides unparalleled response times for simple and complex queries alike, and allows generating even the most advanced visualizations almost instantaneously.
- Relation Extraction. The Recognyze named entity recognition component outperforms comparable systems in its ability to detect persons, organizations and locations in large knowledge repositories, and to capture the evolving relations among these entities.
ASAP FP7 Research Project
The traditional approach to build such analytics platforms is the MapReduce implementation of the Hadoop Framework, and a cloud computing layer to distribute computationally expensive processes. Despite the applicability of the MapReduce model to a wide range of problems, it should not be considered the silver bullet in every situation.
![]() A big data research project to develop an Adaptable Scalable Analytics Platform (ASAP) that started in March 2014 addresses this issue. The ASAP project goes beyond a one-size-fits-all approach by assuming that no single execution model is suitable for all types of tasks, and that no single data store is suitable for all types of data. The ASAP open-source execution framework will provide resource elasticity, synchronization, locality and scheduling abstraction, fault-tolerance, and the ability to handle large sets of irregularly distributed data.
A big data research project to develop an Adaptable Scalable Analytics Platform (ASAP) that started in March 2014 addresses this issue. The ASAP project goes beyond a one-size-fits-all approach by assuming that no single execution model is suitable for all types of tasks, and that no single data store is suitable for all types of data. The ASAP open-source execution framework will provide resource elasticity, synchronization, locality and scheduling abstraction, fault-tolerance, and the ability to handle large sets of irregularly distributed data.
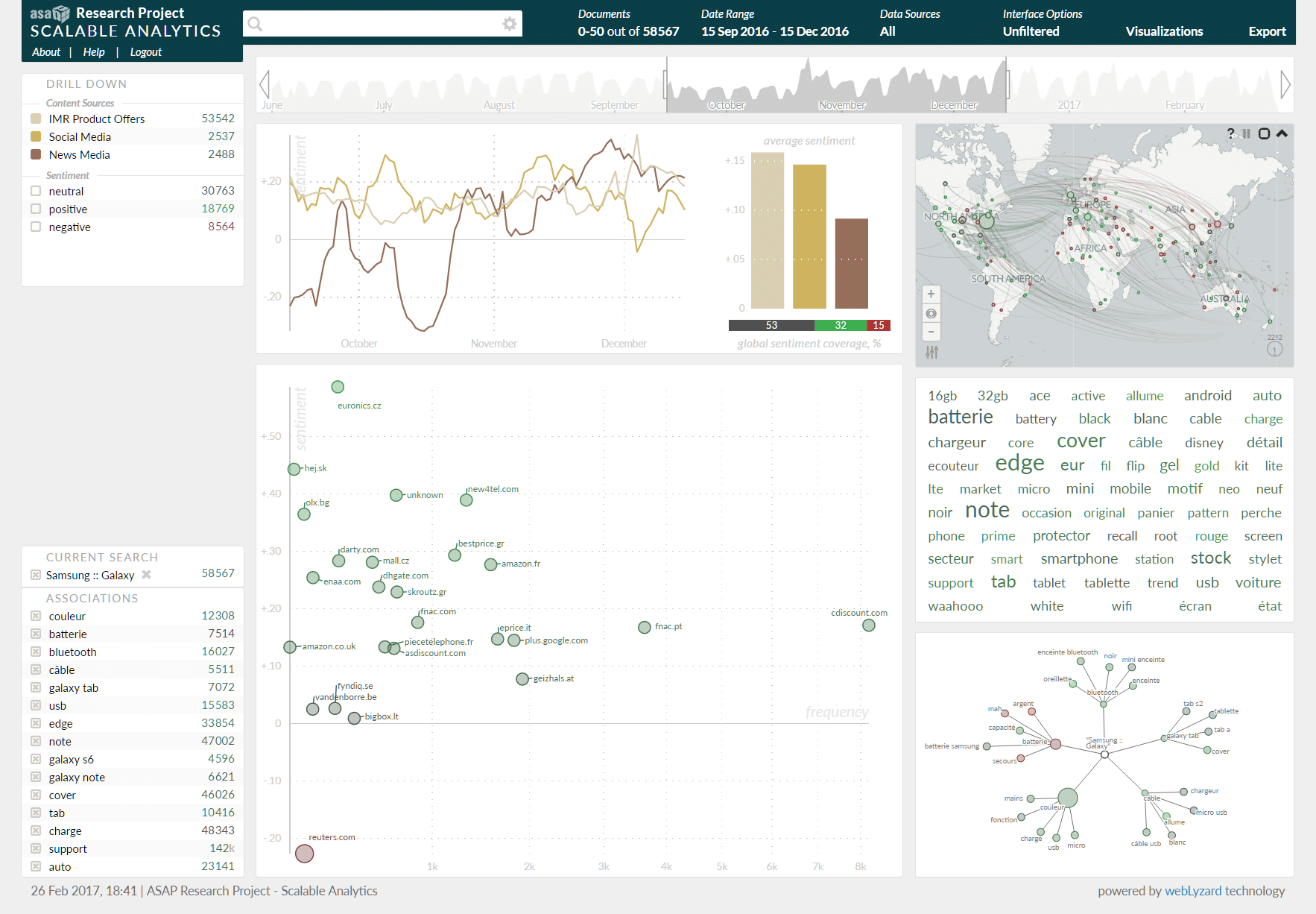
The ASAP dashboard to explore big data repositories is based on the webLyzard visualization engine. The following screenshot shows a drill down sidebar to explore the temporal distribution of metadata within and across content sources. The line chart tracks average sentiment for the Samsung Galaxy product series in product offers, social media postings and news media articles. The bar chart presents the data in aggregated form, and the scatter plot the impact of major content sources. The visualizations of the right sidebar include a geographic map to project the regional distribution of search results, and a tag cloud and keyword graph to reveal associated product features.
Screenshot of the ASAP Dashboard
European Data Value Chain
 Scalable analytics are an important focus of Pan-European research efforts. The flagship initiatives of the European Commission, the 7th Framework Program (FP7) and the new Horizon 2020 Program (H2020), aim to establish and foster European data value chains. To increase the competitiveness of enterprises across all member countries, analytics platforms need to: (i) operate over extremely large amounts of distributed data, (ii) offer sub-second response times over trillions of records, and (iii) visualize results without any perceptible delay for exploring and manipulating these resources.
Scalable analytics are an important focus of Pan-European research efforts. The flagship initiatives of the European Commission, the 7th Framework Program (FP7) and the new Horizon 2020 Program (H2020), aim to establish and foster European data value chains. To increase the competitiveness of enterprises across all member countries, analytics platforms need to: (i) operate over extremely large amounts of distributed data, (ii) offer sub-second response times over trillions of records, and (iii) visualize results without any perceptible delay for exploring and manipulating these resources.
References
- Brasoveanu, A.M.P., Sabou, M., Scharl, A., Hubmann-Haidvogel, A. and Fischl, D. (2017). “Visualizing Statistical Linked Knowledge for Decision Support”, Semantic Web Journal, 8(1): 113-137.
- Scharl, A., Weichselbraun, A., Göbel, M., Rafelsberger, W. and Kamolov, R. (2016). “Scalable Knowledge Extraction and Visualization for Web Intelligence“, 49th Hawaii International Conference on System Sciences (HICSS-2016). Kauai, USA.
- Scharl, A., Herring, D., Rafelsberger, W., Hubmann-Haidvogel, A., Kamolov, R., Fischl, D., Föls, M. and Weichselbraun, A. (2017). Semantic Systems and Visual Tools to Support Environmental Communication, IEEE Systems Journal: Forthcoming.