Search and Content Retrieval
A dashboard search performs a full-text query over the entire document collection (if the global filter is turned off), or within the parameters set by the global filter. Each query returns a list of relevant documents while also updating various context views including the tag cloud, keyword graph, and geographic map.
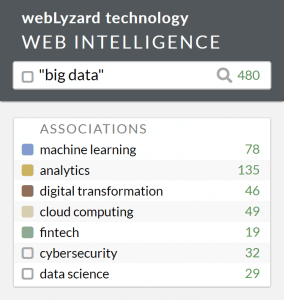 To trigger a search, you can select one or more check boxes in the left sidebar. It is possible to combine check boxes from different categories including bookmarks, associations or metadata attributes. There is also a check box for the global filter text input field located in the upper left corner of the dashboard (with an auto-complete feature to suggest keywords and entities).
To trigger a search, you can select one or more check boxes in the left sidebar. It is possible to combine check boxes from different categories including bookmarks, associations or metadata attributes. There is also a check box for the global filter text input field located in the upper left corner of the dashboard (with an auto-complete feature to suggest keywords and entities).
The system also supports typical wildcard characters, such as the asterisk (*) for representing any number of unknown characters and the question mark (?) for representing exactly one character. More specific search options including Boolean operators for source, location, date and other metadata elements are described in the advanced search section.
Content Categories
The main content area provides the search results in various representations, outlined in the following – either as an interactive visual tool or text-based in the form of lists and tables.

Documents
Once you have triggered a search, the system displays all documents or stories matching the query (as outlined in the story detection section, stories represents clusters of similar documents). The results can be sorted and organized by date, relevance, reach, sentiment and source. To retrieve additional documents, just keep scrolling down the list. The number of matching documents can be seen in the trend chart window.
Clicking on the text block shows an extended quote, a second click activates full-text mode. In this mode the header of the page includes document keywords and the URL of the source, while the footer summarizes the document’s other annotations including source category, source location, target location and sentiment. The floating menu on the left offers an automated summary of the document, with a focus on the document’s most characteristic statements, as well as a metadata view. The latter reveals how the sentiment of a document has been computed by highlighting terms that are contained in the sentiment lexicon (green = positive, red = negative), as well as negation triggers (blue) that reverse the polarity of a sentence.
Sentences
Alternatively, the system lists matching quotes and groups them by document. In addition to the sort options of the Document View, you can sort the results based on sentence-level sentiment as well (indicated by the color of the centered term). The corresponding visual representation is the word tree, an interactive tool for showing the lexical context of search terms.
Sources
Please refer to the cross-media analysis document.
Entities
Similar to the analysis of sources, the dashboard offers a Table View and a Scatterplot to show matching named entities (persons, organizations or locations), which are automatically detected by the Recognyze component. Using the column headers, the table can be sorted by entity name, the number of entity references, and average sentiment towards the entities. Clicking on a row triggers the tool tip to use the selected entity to refine the global filter.
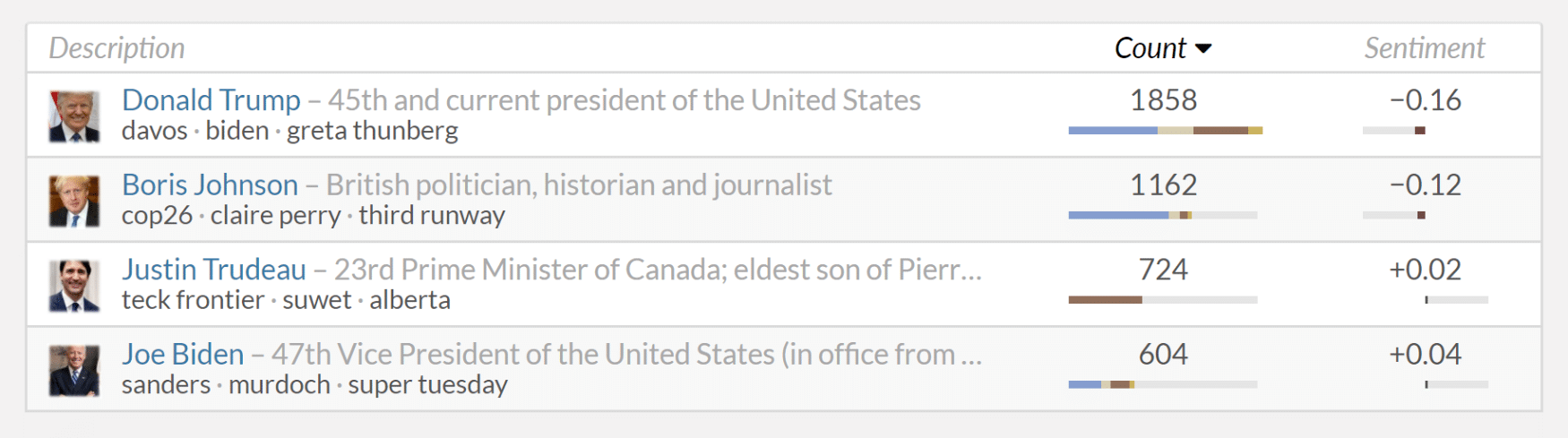
Relations
The last section offers the relation tracker (replacing the previous entity map) as a visual tool to reveal relations among bookmarks, associations, entities and various metadata attributes.
Last major update with release 2020-06 (Sagebrush Lizard).